| photoid | url |
|---|---|
| 29993180834 | https://farm6.staticflickr.com/5641/29993180834_8179c87aa7_z.jpg |
| 7002246829 | https://farm7.staticflickr.com/6240/7002246829_d114f402e7_z.jpg |
| 5466070643 | https://farm6.staticflickr.com/5216/5466070643_759428f4a5_z.jpg |
| 16303185765 | https://farm9.staticflickr.com/8571/16303185765_4dd4d48b7b_z.jpg |
| 30414187771 | https://farm6.staticflickr.com/5503/30414187771_5283977ca6_z.jpg |
| 16065397248 | https://farm9.staticflickr.com/8593/16065397248_7a6a0666b1_z.jpg |
This tutorial describes the workflow and R code that can be used to classify a large number of images into discrete categories, based on their content. The source documents are available on GitHub. This tutorial provides supplementary information to the following publication:
Song, X.P., Richards, D.R., Tan, P.Y. (2020). Using social media user attributes to understand human–environment interactions at urban parks, Scientific Reports, 10, 808. https://doi.org/10.1038/s41598-020-57864-4
An earlier iteration of the code was used in this publication. Note that there are numerous other ways to classify images, including those that deal with overlapping content.
The dataset photos is used as an example. It contains 50 photos with a column of photo source URLs. These are sent to the Google Cloud Vision Application Programming Interface (API), to generate up to ten keyword labels per photo.
Note that you will need to have signed-up with the Google Cloud Platform and generated your Client ID and Client secret. We will be using the googleAuthR and RoogleVision packages to interact with the API.
First few rows of the photos dataset:
Plug-in your Google Cloud Platform credentials:
require(googleAuthR)
options("googleAuthR.client_id" = "xxx.apps.googleusercontent.com")
options("googleAuthR.client_secret" = "")
options("googleAuthR.scopes.selected" = c("https://www.googleapis.com/auth/cloud-platform"))
googleAuthR::gar_auth() #You will be directed to a weblink to sign-in with your account
Generate Keywords
Create a loop to send each photo URL to the Google Cloud Vision API, and append the results to photos:
require(RoogleVision)
#add extra columns for 10 x 3 rows of data (keyword, probability score, and topicality score)
photos[,3:32] <- NA
##Loop##
for(i in 1:length(photos$url)){
te <- getGoogleVisionResponse(photos$url[i], feature="LABEL_DETECTION", numResults = 10)
#If not successful, return NA matrix
if(length(te)==1){ te <- matrix(NA, 10,4)}
if (is.null(te)){ te <- matrix(NA, 10,4)}
te <- te[,2:4]
#if successful but no. of keywords <10, put NAs in remaining rows
if(length(te[,1])<10){
te[(length(te[,1])+1):10,] <- NA}
#Append all data
photos[i, 3:12] <- te[,1] #keywords
photos[i, 13:22] <- te[,2] #probability scores
photos[i, 23:32] <- te[,3] #topicality scores
cat("<row", i, "/", length(photos[,1]), "> ")
}
Keyword results for the first few rows of the photos dataset:
| w1 | w2 | w3 | w4 | w5 | w6 | w7 | w8 | w9 | w10 |
|---|---|---|---|---|---|---|---|---|---|
| tree | nature | vegetation | sky | borassus flabellifer | plant | palm tree | woody plant | arecales | tropics |
| sea | water | wave | ocean | beach | square | calm | surfing equipment and supplies | surfboard | horizon |
| bird | fauna | beak | wren | wildlife | old world flycatcher | piciformes | woodpecker | twig | perching bird |
| plant | flora | leaf | tree | NA | NA | NA | NA | NA | NA |
| sitting | leg | fun | vacation | human body | vehicle | car | hand | muscle | recreation |
| bird | fauna | beak | finch | feather | wildlife | perching bird | NA | NA | NA |
Classify Photos
Next, we prepare the keywords to be used to perform hierarchical clustering of photos. Since hierarchical clustering tends to be very memory intensive, you may want to run the following code on a high performance computing cluster (depending on the number of photos you have). Parallel computing can be used to speed up memory-intensive loops, using the R packages foreach and doParallel.
Set-up your machine for parallel computing:
require(foreach)
require(doParallel)
#setup parallel backend to use many processors
cat("Number of cores = ", detectCores())
cl <- makeCluster(detectCores(), outfile=paste0('./admin/info_parallel.log')) #log file with info
registerDoParallel(cl)
rm(cl)
Before we begin clustering the entire dataset, however, we need to find out how many clusters to group the photos into. If your dataset is large, it may be better to first test the outcomes of different numbers of clusters on a subset of your data. If so, proceed with the following two sub-sections on a random subset of your data, before re-running the first sub-section (A. Distance matrix and clustering) the with the full dataset.
A. Distance matrix and clustering
Extract all the unique keywords across photos (or subset of photos):
words <- unlist(photos[,3:12])
words <- words[!duplicated(words)] #list of unique keywords
Next, we convert photos into a binary format and name it wordscore, with each row representing a photo, and each column representing a keyword. “1” is added if the word is present. We then convert wordscore into a sparse matrix. This will help reduce the load on the computer’s RAM, especially if the photo dataset is very large.
#parallel loop:
wordscore <- foreach(i = 1:length(photos[,1]), .combine=rbind) %dopar% {
vec <- vector(mode = "integer",length = length(words))
a <- match(photos[i,3:12], words)
vec[a] <- 1
cat(paste0(" row ", i), file=paste0("admin/log_wordscore.txt"), append=TRUE) #The loop's progress will be printed in this file
vec
}
colnames(wordscore) <- words
rownames(wordscore) <- NULL
wordscore <- wordscore[,!is.na(colnames(wordscore))] #remove 'NA' keyword if present
library(Matrix)
wordscore <- Matrix(wordscore, sparse = TRUE) #convert to sparseMatrix to save memory
In the binary format, wordscore can now be converted into a distance matrix. To have a fair assessment of the similarity (and thus the distance) between two photos, we need to take into account if they have the same number of keywords generated. The Jaccard Index is used in the calculation, where the number of common keywords is divided by the total number of unique keywords between two photos.
To start with, we find out how many keywords each photo has (up to ten), and save the results as the vector lengword:
narmlength <- function(x){10-sum(is.na(x))} #create function
lengword <- apply(photos[,3:12], 1, narmlength) #apply function
Next, the similarity between each photo and all other photos is calculated manually in a loop, based on the Jaccard Index. Since most photos do not share keywords, the similarity value will tend to be “0” (less strain on computer’s RAM). The similarity matrix (loop output) is then converted into a distance matrix, and subsequently converted into a ‘dist’ object.
simimat <- foreach(i = 1:length(wordscore[,1]), .packages = "Matrix", .combine=cbind) %dopar% {
ws <- wordscore[,which(wordscore[i,] == 1)] #for each photo, find the other photos (rows) with its keywords (cols)
simi <- round(apply(as.matrix(ws),1,sum, na.rm=T)/(lengword+lengword[i]),2) #Jaccard index
simi[1:i] <- 0 #only fill half the matrix
simi[i] <- 1
cat(paste("row",i), file=paste0("admin/log_simimat.txt"), append=TRUE)
simi
}
colnames(simimat) <- NULL
rm(wordscore, lengword)
#convert similarity to distance
distmat <- 1-simimat
rm(simimat)
#Convert to a 'dist' object
dm <- as.dist(distmat)
Finally, we perform hierarchical clustering of photos, using Ward’s distance:
require(fastcluster)
require(graphics)
cluz <- fastcluster::hclust(dm, "ward.D2")
Go to ‘B. How many clusters?’ if the number of photo categories has not been determined.
B. How many clusters?
This section runs as a separate analysis from the final results. Note that the following script may take a long time to run if you have a large dataset.
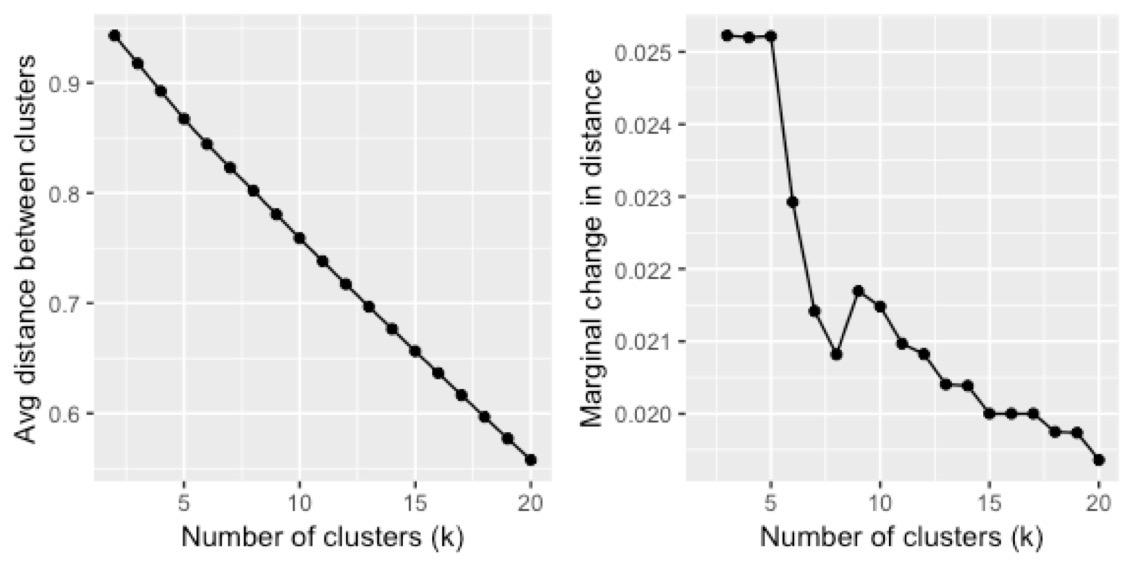
In this analysis, we measure the average difference between within- and between-cluster variation, across different clustering scenarios. Thus, a higher value suggests distinct clusters that are more ‘different’ from each other (i.e. greater variation/distance between clusters). As the number of clusters (k) increases, this value is expected to decrease. We plot these values, and use the L-Method to find the ‘knee’ of the evaluation graph. More information about the L-Method can be found at:
Salvador, S. & Chan, P. Determining the Number of Clusters / Segments in Hierarchical Clustering / Segmentation Algorithms. in 16th IEEE International Conference on Tools with Artificial Intelligence 576-584 (IEEE, 2004). doi:10.1109/ICTAI.2004.50
First, decide up to how many clusters (k) to test for. In this example, we test k from 2 to 20, and save it as the vector scenarios (19 scenarios):
scenarios <- numeric(length(2:20))
Create a function to measure the difference between within- and between-cluster variation across all photos. Run the function for different k values in scenarios.
differ <- function(dist, gr, pos){
#dist is a single photo's vector of distances with all others
#gr is the vector output of grp membership across all photos
#pos is the position of the single photo in length(distmat[1,])
gr2 <-numeric(length(gr)) #vector of "0"s
gr2[gr==gr[pos]] <-1 #Which photos are in same cluster as the photo of interest?
gr3 <- 1-tapply(dist,gr2, mean) #2 values generated: (1) mean distance compared to photos in other clusters, & (2) compared to photos within same cluster. Minus values from one to convert to similarity value.
gr3[2]-gr3[1] #within-cluster minus between-cluster similarity (larger value means clusters are very different)
}
#Run function for different scenarios (numbers of clusters):
for(i in 2:(length(scenarios)+1)){
grp <- cutree(cluz, k=i) #cutree returns vector of grp memberships across all photos
cat("\n<< Working on scenario k =", i, "/", (length(scenarios)+1), ">>\n")
alldiffer <-numeric(length(distmat[,1])) #vector of "0"s"
for(j in 1:length(distmat[,1])){ #run function for each photo (across rows)
alldiffer[j]<- differ(distmat[j,], grp, j )
cat("<row", j, "/", length(distmat[,1]), "photos>")
}
scenarios[i-1]<-mean(alldiffer) #find out the mean difference for each scenario (k)
cat("\n<< Scenario k =", i, "COMPLETE >>")
}
#Create dataframe
scenarios <- cbind.data.frame(seq(2,(length(scenarios)+1),1), 1-scenarios) #convert to distance
colnames(scenarios) <- c("k", "distance")Do note that the small number of photos in our example produces a relatively straight curve. To help with visualisation, we can also calculate the marginal change in the distance:
for(i in 2:length(scenarios$distance)){
scenarios[i,3] <- scenarios$distance[i-1]-scenarios$distance[i]
}
colnames(scenarios) <- c("k","distance","marginalDelta")Here are plots of the results across different clustering scenarios:
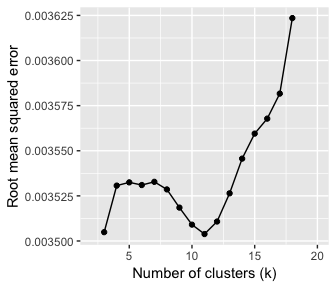
Since such plots may not always allow us to visually determine the appropriate number of photo clusters, we can also use the L-Method as described in Salvador and Chan (2004). To do so, we plot possible pairs of best-fit lines to the curve, and calculate the total root mean squared error (RMSE) for each pair. The lowest RMSE value is used to determine the number of clusters.
require(rgl)
require(qpcR)
#Best-fit line equation:
mod1 <- lm(distance ~ k, data = scenarios)
#Equation from Salvador & Chan (2004):
for(i in 3:(max(scenarios$k)-2)){ #lowest value the 'knee' can be at is 3
rmse <- ((i-1)/(max(scenarios$k)-1)*(RMSE(mod1, which = 2:i))) + (((max(scenarios$k)-i)/(max(scenarios$k)-1))*RMSE(mod1, which = (i+1):max(scenarios$k)))
scenarios[i-1,4] <- rmse
}
colnames(scenarios) <- c("k","distance", "marginalDelta", "Lrmse")
Now we can plot RMSE across an increasing number of clusters (k). In our example, the lowest RMSE value is where k = 11. This is the ‘knee’ of the graph. Note that there are a roughly balanced number of points on either side of this value.
Now it’s time to classify our photos and visualise the categories for good. Go back to ‘A. Distance matrix and clustering’ and re-run the script for the full dataset if a subset of data was used to determine the number of clusters. If not, continue on to the next section…
Visualise Results
Finally, classify the full dataset into 11 clusters:
grp <- cutree(cluz, k=11)
photos <- cbind.data.frame(photos, grp, stringsAsFactors = FALSE) #Final dataframe
##Plot##
plot(as.dendrogram(cluz), sub = "", xlab ="", ylab = "Height", main = "Hierarchical clustering of photos into 11 categories", cex.main = 0.95, leaflab = "none")
rect.hclust(cluz, k = 11, border = "red")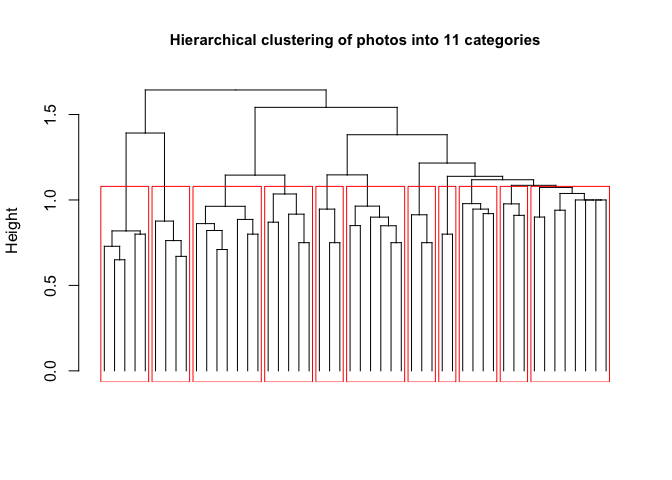
This post is also shared on R-bloggers.com.
Citation
BibTeX citation:
@article{x._p.2020,
author = {X. P. , Song and D.R. , Richards and P.Y. , Tan},
title = {Using Social Media User Attributes to Understand
Human–Environment Interactions at Urban Parks},
journal = {Scientific Reports},
volume = {10},
pages = {808},
date = {2020-01-08},
url = {https://xpsong.com/posts/photo-classify/},
doi = {10.1038/s41598-020-57864-4},
langid = {en}
}
For attribution, please cite this work as:
X. P., Song, Richards D.R., and Tan P.Y. 2020. “Using Social Media
User Attributes to Understand Human–Environment Interactions at Urban
Parks.” Scientific Reports 10 (January): 808. https://doi.org/10.1038/s41598-020-57864-4.